
Hash
해시 함수(Hash function)에 의해 얻어지는 결과물로,
저장소(bucket) 에서 값(value)과 매칭되어 저장됨
해시의 특징
- 임의 길이의 데이터로부터 고정된 길이의 해시값을 계산
- 해시값을 고속으로 계산할 수 있음
- 일방향성을 갖기 때문에(단방향 암호화) 해시값으로부터 Key를 역산할 수 없음
- Key가 다르면 해시값도 달라져야 함
(서로 다른 Key가 같은 해시값을 가지는 것을 '충돌'이라고 함)
그렇다면 해시 함수란?
Hash function
임의의 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 것을 말하고,
매핑전 원래 데이터의 값을 키(key),
매핑 후 데이터의 값을 데이터의 값을 해시값(Hash Value) 또는 해시 코드
매핑하는 과정 자체를 해싱(hashing)이라고 함
해시함수에 대한 개념 정리하기
이전 게시글 제목의 오타가 url로 고정이 되어 조금 보완하여 새롭게 작성하였습니다. 해시함수란 해시함수는 임의의 길이의 데이터를 입력받아 일정한 길이의 비트열로 반환 시켜주는 함수이
velog.io
여기서, 해시함수를 사용해서 변환한 값을 index로 삼아 key와 value를 저장하는 자료구조를
해시 테이블(Hash Table)이라고 함
Hash Table
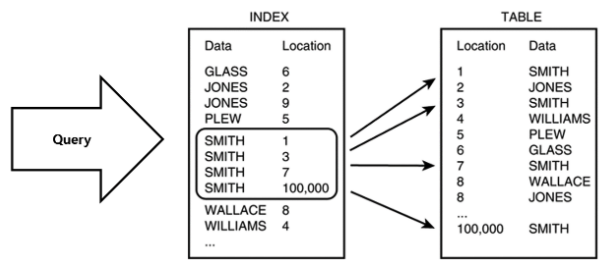
컬럼의 값과 물리적 주소를 key와 value를 한 쌍으로 저장하는 자료구조로,
해시 테이블은 키, 해시함수, 해시, 값, 저장소로 이루어져있음
- 키(Key) - 원본 데이터로, 고유한 값이며 해시 함수의 input이 됨
- 해시 함수(Hash function) - 키(key)를 해시(hash)로 바꿔주는 역할을 함
- 값(Value) - 저장소(bucket)에 최종적으로 저장되는 값
- 버킷(bucket) - 데이터가 저장되는 전체 공간
장점 +
- 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있음
- 배열의 인덱스(index)를 사용해서 검색, 삽입, 삭제가 빠름
- 키(key)와 해시값(Hash)이 연관성이 없어 보안에도 많이 사용
- 데이터 캐싱(Data Caching)에 많이 사용됨
- 중복을 제거하는데 유용
단점 -
- 충돌
- 공간 복잡도가 커짐
- 순서가 있는 배열에는 어울리지 않음
- 해시 함수 의존도가 높아짐
과정
- 원래 데이터의 값(Key)
- Hash Function
- Hash Function의 결과 = Hash Code
- Hash Code를 배열의 Index 로 사용
- 해당하는 Index에 data 넣기
해시 테이블은 키를 해시 함수(hash function) 로 계산하여 그 값을 배열의 인덱스로 사용함.
이때, 해시 함수에 의해 반환된 데이터의 고유 숫자 값을 해시값(Hash Value) 또는 해시코드
key 값을 해시 함수를 통해서 배열의 인덱스로 바꿔주고, 그 자리에 데이터를 저장함
즉, 키(key)는 해시함수(hash function)를 통해 해시(hash)로 변경이 되며 해시는 값(value)과 매칭되어 저장소에 저장이 됨
특징
key값을 이용해 대응되는 value값을 구하는 방식임
실제로 인덱스에서 잘 사용하지 않음
모든 요소들을 하나씩 탐색해야하는 배열과는 달리
key를 통해 데이터를 바로 알아낼 수 있어 저장/읽기 속도가 빨라진다는 장점이 있지만,
저장 공간이 많이 필요하고, 데이터 공간을 작게 잡으면 충돌이 발생(해시 충돌) 할 수 있다는 단점이 있음
- 검색이 많이 필요한 경우
- 저장,삭제,읽기가 빈번한 경우
- 캐쉬 구현시(빠른 중복 체크를 위해)
사용예시
예를 들어 이름을 키(key)로 하여 번호를 저장하는 해시 테이블은 아래와 같이 만들 수 있음
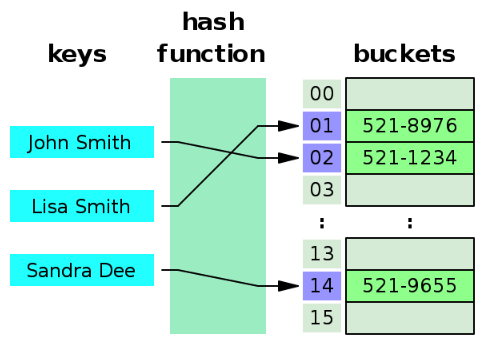
Hash Collision
해시 함수가 서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황으로
다시말해, 서로 다른 입력 키 값이 동일한 해시 값(인덱스)으로 매핑될 경우 해시 충돌이 발생함
해시함수의 입력값은 무한하지만,
출력값의 가짓수는 유한하므로 해시 충돌은 반드시 발생 (비둘기집 원리)
충돌을 처리하는 방식 중 가장 많이 쓰이는 것이 'Separating Chaining'과 'Open addressing' 임
Separating Chaining

버켓 내에 연결리스트(Linked List)를 할당하여,
버켓에 데이터를 삽입하다가 해시 충돌이 발생하면 연결리스트로 데이터들을 연결하는 방식이다.
다시말해, 장소(bucket)에서 충돌이 일어나면 해당 값을 기존 값과 연결시키는 기법임
장점 +
- 한정된 저장소(Bucket)을 효율적으로 사용할 수 있음
- 해시 함수(Hash Function)을 선택하는 중요성이 상대적으로 적음
- 상대적으로 적은 메모리를 사용한다. 미리 공간을 잡아 놓을 필요가 없음
단점 -
- 한 Hash에 자료들이 계속 연결된다면(쏠림 현상) 검색 효율을 낮출 수 있음
- 외부 저장 공간을 사용함
- 외부 저장 공간 작업을 추가로 해야 함
Open addressing

Separating Chaining 의 경우 버켓이 꽉 차더라도 연결리스트로 계속 늘려가기에,
데이터의 주소값은 바뀌지 않는다.(Closed Addressing)
하지만 개방주소법(Open addressing) 은 비어있는 해시(hash)를 찾아 데이터를 저장하는 기법으로
해시 충돌이 일어나면 다른 버켓에 데이터를 삽입하는 방식
개방주소법에서의 해시테이블은 1개의 해시와 1개의 값(value)가 매칭되어 있는 형태로 유지됨
장점 +
- 또 다른 저장공간 없이 해시테이블 내에서 데이터 저장 및 처리가 가능
- 또 다른 저장공간에서의 추가적인 작업이 없음
단점 -
- 해시 함수(Hash Function)의 성능에 전체 해시테이블의 성능이 좌지우지됨
- 데이터의 길이가 늘어나면 그에 해당하는 저장소를 마련해 두어야 함
Reference Path
Hash, Hashing, Hash Table(해시, 해싱 해시테이블) 자료구조의 이해
0_HJVxQPQ-eW0Exx7M.jpeg DATA들이 사용하기 쉽게 정리되어 있다. 자료구조는 도대체 무엇일까? 자료구조(Data-Structure)는 데이터들의 모임, 관계, 함수, 명령 등의 집합을 의미한다. 더 쉽게 표현하자면, 1)
velog.io
[자료구조] Hash/HashTable/HashMap
해시(Hash)/해시 함수(Hash Function)/해싱(Hashing)? 해시(Hash) 란 데이터를 다루는 기법 중 하나이며,해시 함수(Hash Function) 는 데이터를 효율적으로 관리하기 위해서 임의의 길이의 데이터를 고정된 길
hee96-story.tistory.com
'CS' 카테고리의 다른 글
| 정규화 (0) | 2022.12.27 |
|---|---|
| B+Tree (0) | 2022.12.11 |
| Primary Index / Secondary Index / Composite Index (0) | 2022.12.03 |
| 인덱스 Index (0) | 2022.12.02 |
| 마이크로서비스 아키텍처와 모놀리식 아키텍처 (0) | 2022.11.27 |